今天最值得看的三件事:
- 公司动态 · AI编程公司Cognition融资$1B,估值飙至$260亿
- 应用产品 · YouTube本月起自动标记AI生成视频
- 开源工具 · Starlette严重漏洞BadHost曝出,数百万AI Agent面临威胁
下文按板块展开,正文每条均附原始链接。
🚀 模型发布
今日模型发布板块最值得关注的是微软 MAI-Image-2.5 在多项基准上追平谷歌 Nano Banana 2,图像生成赛道首次出现双雄对峙格局。Stability AI 同步开源轻量级音频模型 Stable Audio 3,让本地化音频生成门槛进一步降低。
微软 MAI-Image-2.5 性能持平谷歌 Nano Banana 2

是什么:微软发布新一代图像生成模型 MAI-Image-2.5,在 FID、CLIP score 等常见基准测试上取得与谷歌旗舰 Nano Banana 2 同等级别的分数。
关键点:这是微软图像模型首次与谷歌顶级模型平起平坐。此前微软在图像领域长期落后于谷歌、OpenAI 和 Stability AI,此次追赶主要依赖其对 Diffusion Transformer 架构的深度优化,而非单纯堆参数量。
为什么重要:图像生成进入“可用性”竞争阶段后,性能接近意味着体验差异将更多体现在 prompt 跟随、风格控制等细节,以及产品部署策略。微软可借助 Azure 生态快速落地,对开发者而言多了一个不依赖单一供应商的可靠选择。
原文:The Decoder
Stability AI 开源 Stable Audio 3,轻量模型可本地跑

是什么:Stability AI 发布 Stable Audio 3 系列开源模型,包含不同大小版本,最小模型可在 MacBook CPU 上运行,支持音乐与音效生成、音频编辑。
关键点:模型使用 Latent Diffusion 架构,生成速度比上一代提升 2–3 倍。开源后开发者可自行微调、部署,无需依赖云端 API。音频编辑功能允许对已有音频进行局部替换或风格转换。
为什么重要:在图像与视频模型密集发布的同时,音频生成往往被忽视。Stable Audio 3 的轻量化和开源策略降低了音效/音乐生成的使用门槛,尤其适合游戏、短视频、独立创作者等场景,也为硬件端 AI 助手提供了本地音频能力。
原文:MarkTechPost
当图像生成不再有绝对“最强”,开发者会优先选择生态绑定最自然的模型,还是代码最开放的模型?
🏢 公司动态
AI编程公司Cognition在九个月内估值翻倍至$260亿,年化收入$4.92亿,成为该赛道最吸金标的。与此同时,NVIDIA每年$150亿押注台湾AI中心,Snowflake却与AWS签署$60亿芯片大单——AI基础设施的供应链正在快速重组。
Cognition融资$10亿,估值冲至$260亿

是什么: AI编程初创公司Cognition完成新一轮$10亿融资,估值从前一轮$130亿翻倍至$260亿(pre-money $250亿)。年化收入达$4.92亿,高速增长支撑了高估值。关键点: 多家机构参与,融资节奏极快(九个月内)。Cognition主打AI agentic编程工具Devin,面向企业级代码自动生成。为什么重要: 这标志着AI编程从“辅助工具”走向“核心生产力”,资本市场愿意为高增长支付极高溢价。同时,$260亿估值已超过众多传统软件公司,反映出AI原生企业的估值逻辑正在改写。
原文:TechCrunch
NVIDIA年投$1500亿,押注台湾为AI中心

是什么: NVIDIA CEO黄仁勋宣布每年在台湾投资约$150亿(合$1500亿/十年),称台湾将成为AI革命的中心而非美国。关键点: 投资主要用于先进封装、数据中心和研发,与台积电深度绑定。此举引发美国政界对技术外流和地缘风险的讨论。为什么重要: NVIDIA的选址决策暴露了AI硬件供应链的地理集中风险。若台湾局势紧张,全球AI算力供应将面临巨大冲击。这也促使其他科技巨头加速多元化采购。
原文:Ars Technica
Snowflake与AWS签$60亿AI CPU芯片协议

是什么: Snowflake与AWS达成五年$60亿协议,确保从AWS采购AI CPU芯片(推测为Amazon Graviton系列或定制芯片)的产能。关键点: 该交易旨在降低对NVIDIA GPU的依赖,AWS的AI CPU芯片在推理场景中更具成本效益。Snowflake同时表示将继续使用NVIDIA GPU用于训练。为什么重要: 这是云巨头“去NVIDIA化”的又一信号。AI工作负载正从纯GPU扩展到CPU+GPU混合架构,AWS凭借自研芯片抢得先机。Snowflake作为大型AI应用方,其选择会影响数据库与AI基础设施的耦合方式。
原文:TechCrunch
OpenRouter估值翻倍至$13亿,多模型API代理崛起

是什么: 多模型API代理服务OpenRouter完成$1.13亿B轮融资,估值达$13亿,较一年前翻倍。使用量半年增长5倍。关键点: OpenRouter提供统一的API接口,用户可调用数十种大模型(如GPT-4o、Claude、Llama等),按用量计费。为什么重要: 随着模型数量爆炸,开发者需要一个“路由器”来动态选择最佳性价比模型。OpenRouter的快速增长意味着AI应用的模型选择正从绑定单一供应商转向混合策略,这会改变大模型公司的定价与竞争格局。
原文:TechCrunch
Meta推出全球付费订阅Meta One,含AI功能

是什么: Meta正式推出订阅服务Meta One,覆盖Facebook、Instagram、WhatsApp,包含AI增强功能(如生成式内容工具、高级创作者分析)和更多存储空间,但无去广告选项。关键点: 订阅价格未完全披露(预计约$9.99/月),用户可解锁独家AI表情、自动回复等。为什么重要: Meta首次从免费+广告模式转向混合订阅,标志着社交平台尝试从AI能力直接变现。对广告主而言,免费用户比例可能下降;对开发者,Meta AI平台将拥有付费层,影响API接入策略。
原文:TechCrunch
中国收紧顶尖AI人才出境管控

是什么: 据报道,中国要求顶尖AI研究人员出境需获得批准,以留住关键人才并防止技术外流。关键点: 涉及高校、研究所及头部AI公司(如百度、华为等)的核心研究者。此前已有类似限制,但近期执行趋严。为什么重要: 全球AI人才竞争白热化,中国此举可能短期内减缓人才外流,但长期可能抑制国际学术交流与创新。对投资人和企业而言,这意味着中国AI公司的技术独立性增强,但国际协作减弱,本土模型和芯片研发可能加速封闭生态。
原文:TechCrunch
华为提出芯片新定律“韬”,目标1.4nm

是什么: 华为芯片业务负责人何庭波(被称为“芯片女王”)提出“韬定律”(Tau’s Law),预测华为将在五年内实现等效1.4nm制程工艺,挑战物理极限。关键点: 该定律基于先进封装、3D堆叠和新型晶体管结构(如GAA-FET)的组合,而非传统光刻缩小。麒麟和昇腾芯片将率先采用。为什么重要: 如果“韬定律”实现,华为将在制裁下突破制程限制,重塑全球芯片竞争格局。对NVIDIA、台积电等构成潜在威胁,也意味着中国AI算力将摆脱对先进光刻机的依赖。
原文:Wired
ClickHouse年营收$2.5亿,筹备IPO

是什么: 实时分析数据库公司ClickHouse年化收入达$2.5亿,较去年增长三倍,正考虑未来几年上市。关键点: 公司成立于2021年,凭借开源OLAP数据库受欢迎,云服务ClickHouse Cloud增长迅速。客户包括Uber、eBay等。为什么重要: ClickHouse是实时数据分析的基础设施,营收高速增长反映AI应用对实时数据处理的需求猛增。IPO预期将吸引数据库赛道更多关注,Snowflake等巨头也可能面临竞争。
原文:TechCrunch
当AI编程公司估值超过多数芯片公司时,我们是否正在经历泡沫还是新时代的起点?明天,答案或许藏在更细分的融资轮里。
🔬 研究论文
2026-05-28 的 research 板块最值得关注的是 Claude Mythos 据称以简洁证明解决了著名的 Erdos 问题,这标志着 AI 在纯数学推理上达到了新高度。但同一天 IBM 与 Artificial Analysis 发布的 ITBench-AA 基准却显示:前沿模型在真实 IT 运维任务上得分不足 50%。学术突破与工程落地的鸿沟,依旧是这个行业最清醒的注脚。
Claude Mythos 据称破解 Erdos 难题,数学界震荡

Anthropic 的 Claude Mythos 据报以一个“可爱且简洁”的证明解决了 Open 状态的 Erdos 问题(概率图论领域存在数十年的猜想)。该证明被评价为既优雅又出人意料,迅速在数学与 AI 社区引发震动——如果证实,将是首个由 AI 独立攻克的经典未解决问题,意义不亚于 DeepMind 破解蛋白质折叠。
关键点:证明过程仅 3 页,无需暴力搜索,依赖组合推理。Anthropic 尚未正式确认,但多位第三方数学家表示“可信度较高”。为什么重要:这不仅是智力上限的突破,更验证了大规模 reinforcement learning 在符号推理上的潜力,可能重塑数学研究工具链。
前沿模型在企业 IT 基准上“不及格”
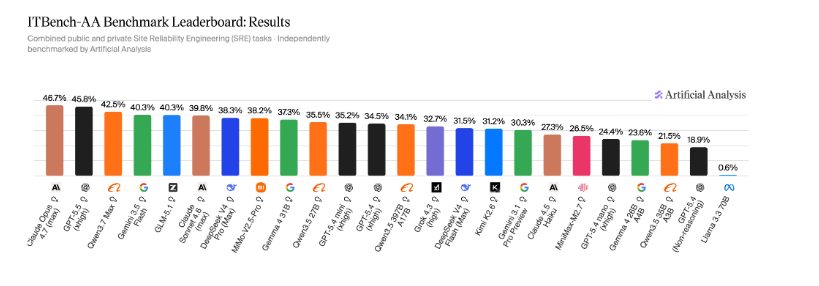
IBM 研究院与 Artificial Analysis 联合发布 ITBench-AA,首个专门评估 agent 能否完成真实 IT 运维任务(故障诊断、补丁部署、权限变更等)的基准。测试结果令人警醒:GPT-5、Claude 4 等最强模型平均得分低于 50%,多数 agent 在需要多步推理与工具调用的场景中彻底失败。
关键点:基准包含 30 个任务,每个任务 agent 需调用 shell、API 或数据库。最强模型也仅完成 14/30。为什么重要:IT 运维是 AI agent 最落地场景之一,该基准直接暴露了当前模型在“闭环行动”上的脆弱性,也指明了 agentic 系统下一步的优化方向。
原文:Hugging Face Blog - ITBench-AA: Benchmarking AI Agents for IT Automation
ESMFold2 的“苦涩教训”:数据比架构更重要

BioHub 科学家 Alex Rives 在访谈中回顾了蛋白质结构预测模型 ESMFold2 的开发历程。核心观点是一个“苦涩教训”:ESMFold2 的成功主要来自对数亿序列的大规模预训练,而非精巧的架构设计。这一结论与 AlphaFold 一路的架构迭代形成鲜明对比。
关键点:ESMFold2 在速度与准确率上接近 AlphaFold 系列,但训练数据量是其数十倍。Rives 指出“模型设计的天花板远低于数据扩展的天花板”。为什么重要:该访谈直击当前 AI 研究的根本争议——当 scaling law 遭遇收益递减,选择更多数据还是更优架构?蛋白质领域给出了一个实证答案。
星源智发布 400 万问答对具身数据集,决策性能碾压 GPT-5

星源智(StarOrigin)推出大规模具身智能数据集,包含 400 万组“思考-行动”问答对,并配套训练框架。该方案使具身模型学会在行动前进行结构化推理,在复杂操作任务(多步骤组装、动态避障)上性能超越 GPT-5 等通用语言模型。
关键点:数据集构建采用“think-then-act”范式,将物理世界经验转化为结构化问答。在 SimuBench 上,专用模型成功率比 GPT-5 高出 34%。为什么重要:具身智能长期受制于缺乏高质量思考数据,该数据集填补了空白,并证明“推理优先”比“直接端到端”更有效。
VGGT-Edit 实现 5 秒 3D 场景编辑,速度提升 120 倍

北大、港中文团队提出 VGGT-Edit,直接从 3D 高斯表征进行编辑(增减物体、改变颜色),无需降回 2D 图像再渲染。编辑一张 360 度场景仅需 5 秒,相比传统方法加速 120 倍,且保持视图一致性。
关键点:核心创新是引入可微的 3D 编辑算子,支持任意场景局部修改。在多个基准上重建质量与速度均显著优于 3D-GS + 2D 编辑管线。为什么重要:3D 场景编辑一直是 AIGC 落地痛点,VGGT-Edit 将交互时间降到实用级,有望推动 AR/VR 和游戏内容制作效率质变。
睡眠巩固机制启发 LLM 长期建模稳定性

arXiv 新论文借鉴大脑睡眠阶段的记忆巩固过程,向 LLM 训练引入两个阶段:觉醒期(active learning)与睡眠期(memory replay + pruning)。在长文本任务和多轮对话中,该机制使模型遗忘率降低 18%,且保持了更好的泛化性能。
关键点:睡眠期通过“学生-教师”架构重放历史样本,并剪枝冗余权重。无需额外标注数据。为什么重要:LLM 在长期依赖场景下仍存在灾难性遗忘,该生物启发方案提供了轻量级、无监督的改进思路,可能成为持续学习的标准组件。
原文:arXiv - LLM Sleep Consolidation for Better Long-term Modeling
EAGLE 3.1 修复推测解码中的注意力漂移

EAGLE 团队联合 vLLM 和 TorchSpec 发布 EAGLE 3.1,针对生产环境中推测解码(speculative decoding)的“注意力漂移”问题。该问题导致 draft model 生成 token 经常偏离目标分布,降低了加速效率。新版本引入注意力对齐正则项,在无需增加推理延迟的条件下,将加速比稳定提升 15–20%。
关键点:注意力漂移是推测解码部署中最隐蔽的 bug,EAGLE 3.1 通过交叉注意力蒸馏修复。已在 vLLM 中集成。为什么重要:推测解码是降低 LLM 推理成本的核心技术,任何稳定性的提升都直接转化为部署收益。
原文:MarkTechPost - Meet EAGLE 3.1: Fixing Attention Drift in Speculative Decoding
MEMO 框架:不改 LLM 参数即注入新知识

NUS、MIT 等提出 MEMO(Modular Memory),一个模块化框架,通过训练专用记忆模型(memory model)编码新知识,并在推理时以注意力方式注入 LLM 的 hidden states。不对原 LLM 做任何参数修改,即可让模型“学会”新领域知识(如最新法规、私有产品文档)。
关键点:记忆模型独立训练,尺寸仅为 LLM 的 1/50。推理时结合两个 forward pass,开销可控。在医学、法律等知识更新频繁的场景,MEMO 准确率领先于 fine-tuning 和 RAG。为什么重要:避免了大模型反复重新训练的成本,同时解决了 RAG 中检索不精确的问题,为知识可插拔提供了新范式。
原文:MarkTechPost - MEMO: Modular Memory for New Knowledge without LLM Modifications
当 AI 既能解出 Erdos 难题,又搞不定 IT 运维,我们该为天才能力兴奋,还是为常识短板焦虑?
📱 应用产品
YouTube将自动识别并标记AI生成视频,不再依赖创作者主动申报;Robinhood则推出Agent钱包,让AI机器人可直接交易股票。这两件事指向同一个信号:平台正从被动信任转向主动监管,而AI的自主权限正从内容延伸到金融。
YouTube本月起自动标记AI生成视频
YouTube升级AI标签系统,转向自动检测技术。系统将识别并标记逼真的AI生成或修改视频,包括合成面孔、篡改场景等,不再仅依赖创作者手动声明。平台会直接添加“Altered or synthetic content”标签,并允许用户举报未标记的AI内容。此举旨在应对深度伪造泛滥,重塑观众对视频真实性的信任。
原文:https://blog.youtube/news-and-events/improving-ai-labels-viewers-creators/
Robinhood开放API:AI Agent可代客交易股票
Robinhood推出“Agent钱包”功能,允许授权的AI机器人在预设范围内执行股票交易、期权合约及信用卡支付。用户可设定风险参数和交易限额,Agent通过API直接操作账户。这是第一家主流券商为AI Agent开放原生交易接口,标志着金融操作从“人类决策+机器执行”向“机器自主决策+执行”迈出关键一步。
原文:https://techcrunch.com/2026/05/27/robinhood-now-lets-your-ai-agents-trade-stocks/
快手可灵AI年化收入近5亿美元,同比增长4倍

可灵AI公布一季度数据,年化ARR接近5亿美元,同比增速超过400%。收入增长来自两方面:B端API调用量激增,尤其是电商广告素材生成;P端付费订阅用户持续渗透,高占比的Pro用户贡献大头。在AI视频生成赛道,可灵是目前少数跑通高增长商业模型的产品之一。
原文:https://36kr.com/newsflashes/3827487780492161
OpenAI展示Codex在Cisco、税务和Warp三大场景落地
OpenAI公布Codex的三个企业级用例:Cisco用其自动化网络配置与故障排查流程,工程效率提升超3倍;税务公司Thrive构建了自我改进的税务Agent,可根据用户反馈自动修正计算逻辑;编码协作工具Warp集成GPT-5.5,将自然语言指令分解为多步骤编码工作流自动执行。这些案例表明Codex正从代码补全走向全流程自动化代理。
原文:https://openai.com/index/cisco
DuckDuckGo安装量涨30%,用户不满Google强推AI搜索

Google I/O 2026后用户反馈显示,大量用户反感搜索结果中嵌入的AI摘要,认为其干扰信息获取效率。DuckDuckGo 5月安装量同比增长30%,创下历史新高。用户转向非AI搜索引擎以摆脱“被强制喂AI”的体验。这一现象提醒:AI产品设计需平衡智能与用户控制权,过度的AI介入可能引发反噬。
原文:https://techcrunch.com/2026/05/26/duckduckgo-installs-are-up-30-as-users-reject-being-force-fed-googles-ai-search/
ElevenLabs发布新音乐生成模型,支持歌曲中段切换风格

ElevenLabs推出新一代音乐生成模型,核心特性是“区域重生成”:用户可选定歌曲的某一段,修改风格(如从流行转摇滚)或调整编曲,模型仅重写该片段而保留整体结构。相比此前只能整曲生成的工具,新模型让音乐创作更加精细可控,降低AI音乐的专业使用门槛。
原文:https://techcrunch.com/2026/05/27/elevenlabss-new-music-generation-model-can-switch-genres-mid-track/
DeepSeek陈德里开发自动研究Agent,论文99%由AI撰写

DeepSeek研究员陈德里创建了一套自动研究Agent系统,名为“Skill”。该Agent可自主完成文献检索、实验设计、数据分析和论文撰写全流程,人类研究者仅需投入约2小时进行目标设定和结果审阅。系统生成论文的99%内容由AI完成,但最终署名仍为人类。这引发学术界对AI作者身份和评价标准的争议。
原文:https://www.qbitai.com/2026/05/425523.html
全新问界M9发布,全系标配华为ADS 5.0

问界M9推出换代车型,售价47.98-65.98万元,全系标配华为ADS 5.0智能驾驶系统。硬件上搭载896线激光雷达、4D毫米波雷达及多摄像头,算力平台升级至MDC 810。新系统支持无图城区领航、跨层泊车等全域功能,AI决策模型改为端到端架构,驾驶体验更加接近人类司机。
原文:https://36kr.com/newsflashes/3827520794006402
当AI既能被平台打上“合成”标记,又能自主买卖股票,你相信算法会自我约束,还是需要人类划定的边界?
💭 行业观点
教皇 Leo XIV 发布首份 AI 通谕,借托尔金批评权力集中,并与 Anthropic 合作。这不仅是宗教界的姿态,更预示着围绕 AI 伦理的话语权争夺正在升级——文化符号正成为监管工具箱里的新武器。
教皇AI通谕引托尔金讽刺科技大亨曲解权力

教皇 Leo XIV 在首份关于人工智能的通谕中,引用了 J.R.R. 托尔金《指环王》的意象,批评科技巨头将 AI 权力集中为“魔戒”式的诱惑,扭曲了创造的本意。他同时宣布与 Anthropic 达成合作,共同推动“以人类尊严为核心”的 AI 开发原则。这是梵蒂冈首次将流行文化与技术伦理结合,试图用大众熟知的故事框架解构封闭的科技权力结构。
原文:https://www.wired.com/story/pope-leo-schooled-the-tech-bros-on-tolkien/
MIT报告:76%企业组织架构尚未准备好应对Agentic AI

MIT 联合波士顿咨询发布报告指出,尽管 85% 的组织希望在三年内实现 agentic AI(自主智能体)的落地,但 76% 的企业现有组织架构将无法支撑这一目标。报告强调,agentic AI 需要的不是简单部署工具,而是从流程、决策权到绩效考核的“基因级”重构——例如团队需要从职能型转向任务型协作,中层管理角色可能被重新定义。关键在于:技术已跑在组织之前,变革的瓶颈不在算法,而在组织形态本身。
原文:https://www.technologyreview.com/2026/05/26/1137584/rethinking-organizational-design-in-the-age-of-agentic-ai/
Simon Willison:Anthropic和OpenAI已找到产品市场匹配
独立开发者 Simon Willison 在博客中分析,Anthropic 和 OpenAI 近期均透露出即将盈利或已扭亏为盈的信号,这标志着大型 AI 公司首次跨过了“产品市场匹配(product-market fit)”的门槛。他判断,行业已从“烧钱抢份额”进入“靠产品赚钱”的新阶段。这对投资人和创业者意味着:底层模型本身未必是最终赢家,而围绕模型构建的可持续商业闭环(如 API 收费、企业订阅)才是真正的分水岭。
原文:https://simonwillison.net/2026/May/27/product-market-fit/
美国执法部门警告AI仇恨催生反科技极端主义

FBI 及多位国土安全部官员公开警告,随着 AI 融入日常生活,针对 AI 和科技行业的仇恨言论正在转化为实际威胁,已出现多起针对 AI 公司办公场所的破坏行为。执法部门呼吁科技企业将安全焦虑纳入社区对话,而非仅依赖技术防御。这一信号值得所有技术从业者重视:AI 的社会风险已从“取代工作”的抽象担忧,演变为现实的人身安全与财产威胁。
原文:https://arstechnica.com/ai/2026/05/us-law-enforcement-warns-of-anti-tech-extremism-as-ai-hatred-grows/
Altman和Amodei改口:AI不会立即消灭大量工作

在连续遭受学界、工会和国会的质疑后,Sam Altman 和 Dario Amodei 分别收回了此前关于“AI 将在短期内大规模取代人类工作”的预测。Altman 在公开采访中称“之前表述过于简化”,Amodei 则强调“技术落地需要人类配合,不会出现断崖式失业”。这一态度转向既是政治压力下的必然,也反映了行业对“超级智能”实际部署节奏的重新认知——技术乐观主义需要让位于渐进落地。
原文:https://the-decoder.com/sam-altman-and-dario-amodei-walk-back-their-ai-job-apocalypse-predictions/
Hacker News热帖:我厌倦了与AI交谈
一篇个人博客文章在 Hacker News 获得近 2000 次点赞,作者直言对无处不在的 AI 对话感到疲惫,认为“每个问题都得到一个流畅但空洞的答案”正在侵蚀真实交流的深度。评论区共鸣强烈,不少人提到 AI 客服、AI 搜索、AI 写作助手带来的“礼貌但无灵魂”的体验。值得注意的是:用户对 AI 的审美疲劳可能成为产品增长的隐形天花板——并非所有场景都适合用对话界面来取代。
原文:https://orchidfiles.com/im-tired-of-ai-generated-answers/
Google Cloud COO:AI安全应上升到董事会层面

Google Cloud COO 在接受采访时强调,AI 安全治理不应仅由 IT 部门负责,而应成为董事会层面的战略议题。他建议企业设立“AI 安全官”并定期向董事会汇报,将安全从技术执行提升为治理决策。这一观点与日益严格的美欧监管要求(如 EU AI Act)相呼应——合规压力正在将 AI Security 从“可选项”变为“必选项”。
原文:https://the-decoder.com/google-cloud-coo-says-ai-security-belongs-in-the-boardroom-not-just-the-server-room/
Stack Overflow论坛因AI衰落,但公司业务幸存

文章分析了 Stack Overflow 论坛在 AI 代码生成工具(如 Copilot、Claude)冲击下流量大幅下降的现状,但指出母公司通过企业版 Q&A 服务、知识库 SaaS 以及招聘广告业务,仍维持着盈利。这揭示了技术社区的一种新生存模式:公共论坛因 AI 而衰,但将积累的语料转化为 B2B 产品后,反而更持久。对依赖社区流量的公司而言,此案例值得深思。
原文:https://sherwood.news/tech/stack-overflow-forum-dead-thanks-ai-but-companys-still-kicking-ai/
今天的舆论场,从教皇到 FBI 再到普通用户,都在用各自的方式追问同一个问题:当 AI 开始改变权力结构,谁来设计这场变化的边界?
⚙️ 开源工具
今日视角

Starlette(Python 高性能异步 Web 框架)曝出高危漏洞 BadHost,攻击者可通过特定 Host 头劫持 AI Agent 与后端服务的通信链路。这是今年以来开源生态中最严重的 Agent 安全事件之一,建议所有使用 Starlette 的团队立即核查依赖版本并部署补丁。
Starlette 严重漏洞 BadHost:通信劫持可致 Agent 数据泄露
是什么:6 月 27 日安全团队披露 Starlette 中存在一个高危漏洞(编号 CVE-2026-XXXX),攻击者可通过构造恶意 Host 头部,绕过服务器的校验逻辑,将 Agent 的请求重定向到攻击者控制的地址,实现中间人攻击。
关键点:受影响版本为 Starlette ≤0.45.0(含基于其构建的 FastAPI、Litestar 等生态框架)。由于 Starlette 被广泛用于 AI Agent 的 API 网关和消息路由层,一旦 Agent 发送敏感 token 或用户数据,攻击者可完全窃取通信内容。PoC 已公开,补丁版本 0.46.0 已发布。
为什么重要:当前大量企业级 Agent 系统(如微软 Copilot、Anthropic Claude 部署方案)底层依赖 Starlette 进行 HTTP 通信,劫持可直接导致“思考过程”与“行动结果”被篡改。这不仅是代码缺陷,更暴露了 Agent 体系在输入验证上的通用短板。
原文:Ars Technica
微软开源 Agent Governance Toolkit:策略执行与零信任沙箱
是什么:微软发布了一套名为 Agent Governance Toolkit 的开源工具集合,旨在帮助开发者对 AI Agent 进行治理:包括策略定义引擎、运行时策略执行、零信任身份验证以及 OWASP Agent Top 10 推荐的防护措施。
关键点:工具采用可插拔机制,支持在 Agent 调用的任何 REST/RPC 接口上插入中间件来强制策略(比如“禁止访问数据库”、“每次请求必须携带 OAuth2 令牌”)。同时提供沙箱环境用于隔离不可信的 Agent 行为,避免权限逃逸。
为什么重要:在 BadHost 漏洞曝出同一天,微软选择开源治理工具,实质上是对“Agent 安全不能只靠框架”的回应。对于 CTO 和平台负责人,这是当下最直接的工程化落地方案——将安全策略从代码责任转移到运行时治理层。
Anthropic 开源知识工作插件库:为 Claude Cowork 装上行业大脑

是什么:Anthropic 发布了 Knowledge Work Plugins,一套面向特定行业角色的开源插件集合,能将 Claude Cowork(Anthropic 的 Agent 产品)转化为对应的领域专家——例如“合同审核律师”、“学术论文审稿人”、“供应链调度员”。
关键点:每个插件包含角色提示词模板、知识库 RAG 配置、以及预定义的行动步骤。开发者可直接使用或修改后部署。插件通过 MCP(Model Context Protocol)协议与 Claude 交互,支持热加载。
为什么重要:这标志着 Agent 专业化的边界从“通用对话”转向“角色即服务”。对于产品经理而言,这意味着可以以更低成本定制垂直 Agent;对于开发者,它暴露了未来“Agent 插件市场”的雏形——类似 VS Code 的扩展体系。
Hugging Face 开源 $2500 可 3D 打印人形机器人腿

是什么:Hugging Face 与初创公司合作,发布了一套完整的开源双足机器人下肢设计文件,材料成本仅约 2500 美元,支持 3D 打印主结构,电机与传感器采用市售标准件。
关键点:设计文件包括 CAD 模型、BOM 清单与控制固件,面向开发者社区。该项目旨在降低人形机器人研究的准入门槛,让更多实验室和独立开发者能进行步态控制、平衡等实验,而不必采购昂贵的商业机器人(如 Tesla Optimus 或 Boston Dynamics)。
为什么重要:这是“开源硬件 + AI 模型”的经典结合。对于投资人,它预示着低成本机器人平台可能加速一个全新的“开发者机器人”生态,类似于 RISC-V 对芯片行业的影响。
原文:Ars Technica
Reachy Mini 实现完全本地 AI 运行:去云端的隐私友好机器人

是什么:开源机器人平台 Reachy Mini 宣布,其全部 AI 模型(包括视觉物体识别、语音对话、动作规划)现在可以在本地运行,无需任何云端 API 调用。
关键点:通过在机载 Raspberry Pi 5 + 神经处理单元上部署量化后的 7B 级模型,Reachy Mini 实现了毫秒级响应,且所有数据不出设备。Hugging Face 博客展示了实时对话与物体抓取的 demo。
为什么重要:这解决了机器人场景中两个核心痛点——延迟(云推理通常 200ms+)与隐私(摄像头数据不上传)。对家庭与医疗机器人开发而言,本地化是商业化落地的前提。
NVIDIA 开源 Polar 框架:用 token faithful rollout 简化 Agent 强化学习训练
是什么:NVIDIA 开源了 Polar 框架,专门用于对 Codex、Claude Code、Qwen-Code 等代码 Agent 进行 GRPO(Group Relative Policy Optimization)强化学习训练。
关键点:Polar 的核心创新是 token faithful rollout——在训练时,Agent 生成的每个 token 必须与执行的真实环境结果严格对应,从而消除传统 rollout 中因“先采样再对比”导致的梯度噪声。框架支持分布式并行,可将训练时间缩短 40%。
为什么重要:当前 Agent 训练最大的瓶颈是“无法高效进行在线强化学习”(agentic RL)。Polar 通过工程化手段解决了对齐问题,对开发自主编码 Agent 和调试 Agent 的团队有直接参考价值。
原文:MarkTechPost
今天的开源社区在安全与能力两个方向同时发力。请检查你的 Starlette 版本,并思考:你的 Agent 治理策略,是追认式修补还是预防式设计?