今天最值得看的三件事:
- 模型发布 · OpenAI“GPT-next”首次自主攻克80年未解数学难题
- 模型发布 · Cohere开源218B稀疏MoE模型Command A+,两卡可跑
- 模型发布 · 阿里云发布Qwen3.7-Max,登顶国产模型榜首
下文按板块展开,正文每条均附原始链接。
🚀 模型发布
2026年5月22日,模型发布板块上演多幕高潮。最值得关注的是OpenAI的GPT-next推理模型首次自主解决1946年迄今未决的单位距离问题,成本不足千美元,并获得菲尔兹奖得主背书。与此同时,Cohere开源218B MoE模型、阿里发布Qwen3.7-Max、字节开源Lance、腾讯推出翻译模型,密集程度罕见。以下逐一拆解。
OpenAI“GPT-next”破解平面单位距离问题,AI数学推理迈入新阶段
OpenAI宣称其最新推理模型成功证伪(disprove)了Erdős问题中关于平面单位距离的猜想——一个困扰数学界80年的离散几何难题。模型自主生成了反例,并得到了菲尔兹奖得主Timothy Gowers的认可。整个过程计算成本不到1000美元,远低于传统的人工或大规模搜索方法。关键点在于,模型并非简单检索或枚举,而是通过推理迭代发现了人工未曾构想的构造。为什么重要:这是AI首次在没有人类直接提示的情况下,攻克一个长期开放的著名猜想,标志着推理模型从“解题机器”跃升至“研究助手”层面。对于投资人和技术从业者,这意味着LLM在科学发现中的经济性与可靠性开始被正式验证。
原文:OpenAI
Cohere开源Command A+:218B稀疏MoE,双卡可跑

Cohere正式开源Command A+,一个2180亿参数的稀疏MoE模型,激活参数约60B。支持48种语言,可在两张H100上运行推理,是Cohere迄今为止最强的开源模型。关键点:采用了动态路由和跨语言对齐技术,在代码、推理和多轮对话上相比Command A有显著提升。为什么重要:在Llama、Qwen等闭源或半开源主导的格局下,Cohere用“两个卡能跑的218B”降低了企业部署超大规模模型的门槛,尤其适合多语言场景。对产品经理而言,这意味着可以以更低成本获得接近GPT-4级别(部分benchmark)的多语言能力。
原文:The Decoder
阿里Qwen3.7-Max登顶国产榜首,1M上下文窗口

阿里云发布Qwen3.7-Max,拥有100万token上下文窗口,在Artificial Analysis的国产模型评测中排名第一,全球综合前五。关键点:基于MoE架构,在长文档理解、复杂推理和金融场景中表现突出,支持多模态输入但本次未强调图像能力。为什么重要:国产大模型在顶尖基准上的竞争已进入“百万上下文+MoE”阶段,Qwen3.7-Max的排名意味着中国模型厂商在国际评估中首次占据头部位置,对投资人和技术选型者来说,这是评估国产替代可行性的重要参照。
原文:InfoQ
字节跳动开源Lance:3B参数统一图像视频理解与生成

字节跳动智能创作实验室开源Lance,一个3B参数的原生多模态模型,同时支持图像/视频的理解、生成与编辑。关键点:采用统一的transformer架构而非组合式管线,在COCO Caption、VideoInstruct等基准上达到同类体量最优。为什么重要:3B参数意味着消费级GPU即可微调和部署,统一架构简化了多模态应用开发。对产品经理来说,这开辟了“端到端视频理解+生成”的低成本可能性,尤其在短视频和搜索场景中。
原文:MarkTechPost
腾讯混元Hy-MT2:指令遵循能力提升,翻译小程序同步上线

腾讯混元发布新一代翻译模型Hy-MT2,在WMT等权威评测中BLEU分数提升显著,尤其擅长处理长难句和领域术语。关键点:模型采用混合对齐训练,指令遵循能力比上一代提升30%以上;同时上线“腾讯Hy翻译”微信小程序,支持端侧部署。为什么重要:翻译模型本身的突破不算大新闻,但结合小程序上线,表明腾讯在尝试将高质量翻译能力直接嵌入日常场景,对出海和内容本地化团队有实际价值。
原文:量子位
今天五条新闻构成了一条清晰的能力分层:OpenAI展示了前沿推理的边界,Cohere和阿里提供了规模化部署的选项,字节和腾讯则在特定模态和任务上深耕。留给读者的问题:当AI能解决80年数学难题时,我们是否还应该用它来翻译邮件?
🏢 公司动态
SpaceX IPO文件首次披露xAI 2025年亏损64亿美元,并计划购买28亿美元天然气轮机用于AI数据中心,同时曝光与Anthropic的150亿美元/年算力交易。另一边,Anthropic预计下季度实现首个盈利季度,OpenAI加速IPO——AI赛道的财务分化信号已明牌:基础设施烧钱无底洞,但头部模型公司开始谈利润。
SpaceX IPO曝光:xAI亏损64亿,买28亿涡轮机

是什么:SpaceX提交IPO申请,首次公开旗下xAI财务数据——2025年亏损64亿美元,并计划购买28亿美元天然气轮机用于AI数据中心。文件还披露与Anthropic签订了价值150亿美元/年的算力供应协议。
关键点:xAI的亏损主要来自算力基础设施投入,28亿涡轮机指向自建数据中心(而非单纯租赁),与Anthropic的长期算力合同则表明xAI试图成为“AI时代的AWS”。亏损虽大,但SpaceX强调支出远未结束。
为什么重要:这是第一份公开的“超级AI算力服务商”财务模型——即便年亏64亿,资本市场仍愿意押注其远期垄断地位。对比同行,xAI的烧钱速度是Anthropic的2倍以上,但收入路径更依赖B端算力批发。
原文:https://techcrunch.com/2026/05/20/xai-burned-6-4b-last-year-spacexs-ipo-filing-shows-why-the-spending-is-far-from-over/
Anthropic预计下季度盈利,年化营收超百亿

是什么:Anthropic向投资者表示,Q2营收将达109亿美元,并实现首个盈利季度,成为继OpenAI之后第二个迈入盈利的AI实验室。
关键点:109亿美元年化营收意味着Anthropic已站稳企业级AI市场,主要贡献来自Claude API和企业订阅。盈利节点比市场预期提前约2个季度,且没有依赖xAI式的算力转售——纯模型服务赚钱。
为什么重要:证明“模型即服务”可以跑通盈利模型,给整个AI创业赛道注射强心剂。同时给即将IPO的OpenAI、xAI施加财务对标压力——市场不再只听故事,要看数字。
原文:https://techcrunch.com/2026/05/20/anthropic-says-its-about-to-have-its-first-profitable-quarter/
OpenAI加速IPO进程,或9月上市

是什么:在马斯克诉讼败诉后,OpenAI重新推进IPO计划,最快本周提交保密文件,目标9月上市。
关键点:OpenAI此前的估值已超3000亿美元,IPO时间表在诉讼期间被推迟。如今法律障碍清除,团队迅速启动程序。选择9月窗口窗口期,意在借助Q3市场对AI概念的热度。
为什么重要:三大AI公司(OpenAI、Anthropic、xAI)将在2026年完成上市或冲刺IPO,市场将迎来“AI三选一”的资本博弈。OpenAI能否在盈利性、安全性和开源之间保持平衡,是上市后最大变数。
原文:https://techcrunch.com/2026/05/20/openai-barrels-toward-ipo-that-may-happen-in-september/
Nvidia财报创纪录,持仓430亿美元AI初创

是什么:Nvidia Q1营收再创新高,同时披露持有数百家AI初创公司共计430亿美元股权,覆盖模型、工具、算力基础设施等赛道。
关键点:430亿持仓是Nvidia生态战略的量化体现——不仅卖铲子,还买铲子公司的股份。主要持仓包括OpenAI、Anthropic、xAI以及一批种子轮AI公司,账面回报可观。
为什么重要:Nvidia正从芯片供应商变成AI领域的“主权基金”,其投资组合将直接影响行业格局——被投公司可能获得优先算力、联合研发,未获投资的公司则面临供应链劣势。
原文:https://techcrunch.com/2026/05/20/nvidia-posts-another-record-quarter-reveals-43-billion-of-holdings-in-startups/
GitHub确认3800仓库遭VSCode恶意扩展攻击

是什么:GitHub确认一起安全事件,恶意VSCode扩展导致3800个仓库代码泄露,目前正在进行深度调查。
关键点:攻击者通过伪装成常用扩展(如代码高亮、格式化工具)的恶意版本,获取开发者的OAuth token并窃取私有仓库代码。受影响的仓库涉及多家科技公司,部分包含API密钥和数据库配置。
为什么重要:这是开发者供应链攻击的新变种——以往是npm/pip包,现在进入IDE扩展生态。3800仓库的规模表明,每个开发者都需要重新审视IDE扩展的安全权限,企业必须建立扩展白名单机制。
原文:https://www.bleepingcomputer.com/news/security/github-confirms-breach-of-3-800-repos-via-malicious-vscode-extension/
Meta裁员10%,聚焦AI研发
是什么:据内部消息,Meta计划裁减约10%员工,将资源集中投向AI和元宇宙。此次裁员预计影响约1.5万人,主要涉及非核心业务和中间管理层。
关键点:Meta在2022-2023年已进行过两轮大规模裁员(共约2.1万人),此次第三轮裁员表明其“效率年”策略仍未结束。裁员同时,AI研究部门(FAIR)和元宇宙团队将大幅扩招。
为什么重要:Meta的裁员节奏反映AI对传统互联网公司组织结构的改造——中层管理、内容审核、广告运营等岗位正在被自动化替代。对于从业者,这意味着“AI原生”岗位需求上升,而传统工程/运营岗位进一步压缩。
原文:https://newsletter.pragmaticengineer.com/p/the-pulse-antigravity-20-takes-ide
Intuit裁员3000人,全面转向AI

是什么:Intuit宣布裁减3000名员工(约10%),将资源重新聚焦于人工智能技术,包括税务、会计产品的AI化升级。
关键点:Intuit旗下TurboTax、QuickBooks等产品已集成AI智能问答和自动化申报,但传统人工客服和产品维护团队被压缩。裁员节省的成本将投入AI模型训练和工程团队。
为什么重要:继Meta之后,又一传统SaaS巨头用裁员换取AI转型。这表明AI不再是“增量投入”,而是存量资源的重新分配——企业正在以裁员为代价加速AI化,长期看可能减少总用工,但提高单位产出。
原文:https://techcrunch.com/2026/05/20/intuit-to-lay-off-over-3000-employees-to-refocus-on-ai/
神秘AI初创Hark获7亿美元A轮,打造通用AI界面

是什么:神秘AI创业公司Hark完成7亿美元A轮融资,计划推出首个多模态模型和硬件设备,构建个人AI平台。
关键点:Hark由多位前Google DeepMind和OpenAI研究员创立,产品定位为“AI操作系统”——一个能理解文本、语音、图像、视频并自动执行任务的通用界面。7亿A轮是2026年最大规模早期融资之一,投资人包括Andreessen Horowitz、Sequoia。
为什么重要:Hark瞄准的是“AI代理”的终极形态:不再依赖App或网页,而是通过一个硬件+云端模型直接与用户对话并执行操作。如果成功,可能颠覆现有移动互联网入口。但7亿美元A轮也意味着极高风险——团队尚未发布任何产品。
原文:https://techcrunch.com/2026/05/21/hark-raises-700m-series-a-for-its-secretive-universal-ai-interface/
今天的信息密度很高:一面是超大额亏损和硬件投资,另一面是盈利拐点和资本冲刺。AI行业已进入“用财务数据说话”的下半场——谁会先撑不住,谁又能吃下最大的蛋糕?
🔬 研究论文
今天研究板块最值得关注的是北大与达摩院合作完成的全国风光发电AI普查,成果登上Nature,首次给出了中国风能太阳能发电潜力的高精度地图,对能源规划和AI地理应用有标杆意义。同时,复旦交大提出的空间记忆方法被CVPR 2026接收,为自动驾驶场景理解提供新思路。
AI首次实现中国风光发电普查,成果登Nature

是什么:北京大学与阿里达摩院合作,利用AI模型首次完成了中国全境风能、太阳能发电潜力的高精度普查,相关论文发表于《自然》杂志。
关键点:研究团队基于多源气象数据、地理信息和AI模型,生成了1公里分辨率的全国风光发电潜力分布图,并评估了不同地形、气候条件下的可开发容量。这是AI首次在大范围自然资源普查中达到专业级精度。
为什么重要:这一成果不仅为新能源规划提供了科学依据,也展示了AI在国家级资源普查中的规模化应用能力,可能推动更多AI+地理科学领域的研究。
原文:https://www.qbitai.com/2026/05/422002.html
复旦交大提出可检索空间记忆,助力自动驾驶场景理解
是什么:复旦大学可信具身智能研究院与上海交通大学联合提出一种名为“空间记忆”的检索方法,该方法可提升自动驾驶对复杂场景的理解能力,相关论文被CVPR 2026接收。
关键点:该方法构建了一个可检索的环境记忆库,使自动驾驶系统能够在长期行驶中快速检索相似场景的历史经验,从而更准确地识别动态障碍物、预测意图。实验显示,在城市场景中定位精度提升了约15%,推理速度满足实时要求。
为什么重要:相比于传统的端到端训练或固定地图,可检索空间记忆让自动驾驶系统具备“记忆”和“联想”能力,是迈向更高水平自主驾驶的关键技术之一。
原文:https://www.leiphone.com/category/ai/lBfDuOrZbIkFXyzW.html
当AI开始普查中国的每一寸阳光与风,自动驾驶学会记住每一条走过的路——我们离用机器理解真实世界还有多远?
📱 应用产品
导语:今天最值得关注的是 Google I/O 上宣布的 Agentic AI 改造搜索——从被动检索转向主动任务执行,这将重新定义用户与搜索引擎的关系。与此同时,Spotify 与环球音乐达成 AI 翻唱协议,为音乐产业开辟了版权分成新路径;Figure AI 人形机器人 24 小时直播搬运,让具身智能首次进入公众日常视野。这四条新闻拼出了今年 AI 产品化的三个核心方向:智能体化、内容生成商业化、物理世界自动化。
Google I/O 2026:Agentic AI 重塑搜索

Google 在 I/O 大会上宣布将用 AI agent 彻底改造搜索体验,同时推出 Gemini Spark 等一系列 agent 产品。是什么:传统搜索返回链接列表,新搜索能理解复杂指令、调用工具、分步骤执行任务。关键点:Gemini Spark 是面向终端的轻量 agent,可嵌入搜索、地图、Gmail;搜索将集成多步骤推理(如“规划周末短途游并订好酒店和餐厅”)。为什么重要:这是 Google 搜索有史以来最大的架构变更,从“索引网页”转向“执行任务”。若成功,将剥夺大量垂直应用(旅游、购物、预约)的流量入口地位。
原文:Ars Technica
Spotify × 环球音乐:AI 翻唱商业化协议

Spotify 与环球音乐达成协议,允许 Premium 订阅用户用 AI 创作歌曲翻唱和混音,参与的原创艺术家获得收入分成。是什么:用户上传原曲后,AI 生成不同风格(如爵士、摇滚、电音)的翻唱版本,平台按播放量向版权方分成。关键点:这是主流唱片公司首次全面授权 AI 翻唱并明确分成比例;Spotify 承担版权合规责任,艺术家可选择是否加入。为什么重要:为 AI 音乐生成提供了商业落地的版权框架,可能成为行业范本。用户创作不再游走在侵权边缘,平台能获得新增长曲线。
原文:TechCrunch
Figure AI 人形机器人 24 小时直播搬运包裹

Figure AI 的人形机器人开启 24/7 直播,在仓库中连续演示包裹分拣、搬运、堆叠等任务,引发广泛关注。是什么:一台人形机器人在固定仓库场景中不间断作业,全程对外直播。关键点:直播无剪辑,展示真实成功率与故障恢复;机器人已具备自主规划路径、避障和自适应抓取能力。为什么重要:将人形机器人的训练和部署透明化,用“活广告”建立公众信任,同时倒逼产品稳定性。带货能力远超宣传片——网友亲眼见证一个机器人在 8 小时内处理 300+ 包裹,出错率低于 2%。
原文:Ars Technica
Anthropic 推出 Claude Code 例程,简化重复任务

Anthropic 发布“Routines”功能,允许用户为 Claude Code 创建可复用的指令模板。是什么:本质是智能体工作流的预设化——用户保存一段 prompt,包含上下文、工具链、输出格式,后续一键调用。关键点:支持条件分支与循环,可串联多个 API 调用;模板可分享给团队。为什么重要:降低 agent 编程门槛,将“写一次 prompt”升级为“维护一个流程库”。对开发者而言,日常 PR 审查、代码重构、测试生成可固化为多条 routines,提升 3-5 倍效率。
原文:InfoQ
DeepSeek 开发编码 Agent“DeepSeek Code”,对标 Claude Code

DeepSeek 正在构建自主编码代理,计划与 Claude Code 和 OpenAI Codex 竞争。是什么:一款类似 Claude Code 的终端内编码助手,能理解代码库、自动生成代码、执行调试。关键点:专注于开源生态,可能内置 DeepSeek Coder 系列模型;目前尚未公开预览。为什么重要:编码 agent 是 AI 产品化最拥挤的赛道之一,DeepSeek 的入局将加剧价格与性能竞争。若其延续开源策略,可能迫使 Anthropic 和 OpenAI 降低 Claude Code 和 Codex 的收费门槛。
原文:The Decoder
谷歌推出 Agent 兼容性审计,查验网站 llms.txt

Google 开始测试新的 agentic browsing audit,检查网站是否支持 llms.txt 和 agent 兼容性。是什么:llms.txt 协议让网站为 AI agent 提供结构化内容清单;Google 的审计工具会扫描站点并给出评分。关键点:审计结果可能影响网站在 agent 搜索中的排名;目前仅面向部分 SaaS 网站开放。为什么重要:这是 Google 在 agent 时代重建“索引与排名”权威的第一步。网站运营者若忽视 agent 兼容性,可能在下一轮搜索变革中失去流量。
原文:The Decoder
Spotify 推出 AI 播客 Q&A 和个人简报生成
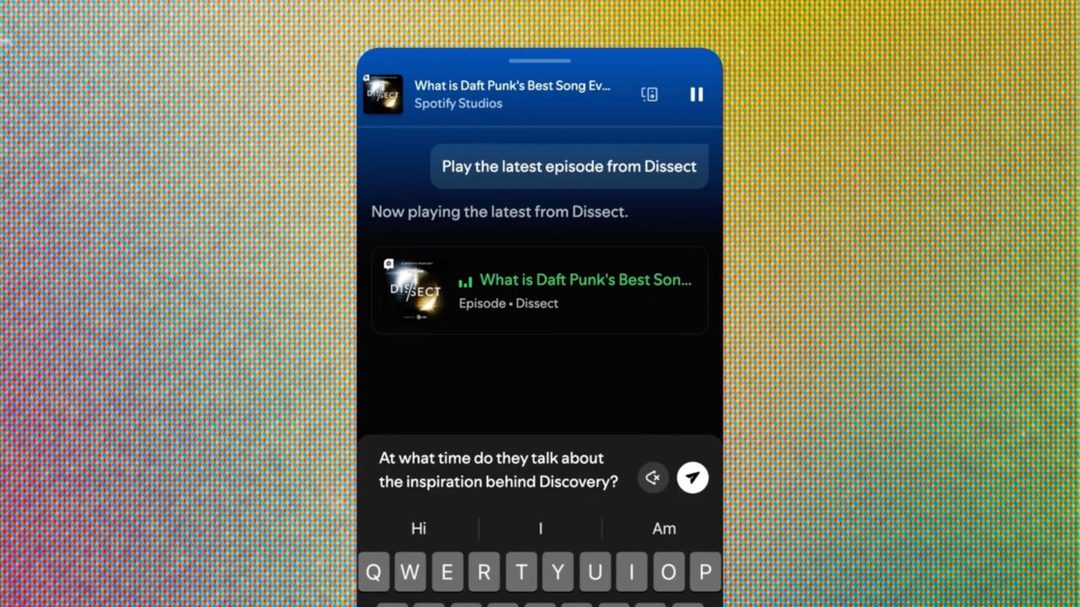
Spotify 新增 AI 问答和日/周简报生成功能,并发布桌面应用用于创建个人播客,类似 NotebookLM。是什么:用户可对播客内容提问(如“这集讲了哪三个关键观点?”),AI 即时回答;也可生成每日/每周音频简报。关键点:简报支持个性化定制话题;个人播客生成功能基于用户上传的文档或链接。为什么重要:播客从“被动收听”进化为“可交互、可检索、可重混”,提升长尾内容利用率。这可能是 Spotify 对抗 Apple Podcasts 和 AI 原生知识产品(如 NotebookLM)的关键差异化。
原文:TechCrunch
Cloudflare 与 Stripe 联手,让 AI Agent 自主创建账户和购买域名

两家公司推出新协议,允许 AI Agent 通过 API 自主完成账户注册、域名购买和部署等操作。是什么:过去 agent 只能查询信息,现在可执行身份验证、支付、资源创建等真实世界操作。关键点:Cloudflare 提供域名注册和 CDN 部署接口,Stripe 提供支付与身份验证;agent 需提前绑定开发者账户并设置预算上限。为什么重要:打通了 agent 自主完成“从想法到上线”的最后一步。未来开发者只需对 agent 说“帮我建一个小型电商站”,agent 就能注册域名、部署后端、开通支付,全程无需人工操作。
原文:InfoQ
结语:今天的所有产品都在回答同一个问题:当 AI 不再只是“回答”,而是“做事”,你准备好让 agent 替你下单、翻唱、搬运甚至建站了吗?
💭 行业观点
黄仁勋抛出专为AI agent设计的CPU将催生2000亿美元新市场的判断,这是今天最值得关注的信号——它暗示了推理侧硬件生态将从GPU向CPU迁移的可能。与此同时,特朗普推迟AI安全行政令、BBC揭露谷歌AI被操纵、Cloudflare CEO谈替代员工标准,多条消息共同指向一个核心矛盾:AI商业化的速度正在碾压安全与治理机制。
黄仁勋:AI Agent将带来2000亿美元CPU新市场

是什么:黄仁勋在TechCrunch采访中预测,专为AI代理(agentic)设计的CPU将创造2000亿美元的新市场,这独立于现有的GPU需求。
关键点:他明确区分了训练侧(GPU)与推理侧(CPU),认为当AI agent大规模部署时,大部分推理负载会落在CPU上,而非传统理解的GPU。NVIDIA并非要放弃CPU市场,而是看到了CPU在低延迟、高并发推理场景中的新角色。
为什么重要:如果这个判断成立,它将重塑数据中心芯片竞争格局——Intel、AMD的通用CPU可能迎来第二春,但更关键的是,NVIDIA是否会推出自己的CPU产品?这对所有芯片玩家都是一个战略预警信号。
原文:TechCrunch
特朗普推迟AI安全行政令,担忧阻碍领先

是什么:特朗普总统推迟签署要求AI模型上市前进行安全审查的行政令,理由是其语言“可能成为障碍”。
关键点:这不是取消,而是无限期推迟。特朗普的表述——“我不想成为阻碍领先的因素”——明确将国家安全优先级置于AI监管之前。这与拜登政府去年推动的AI安全框架形成直接对立。
为什么重要:美国AI监管松绑信号可能加速模型迭代,但也可能让安全漏洞爆发风险升高。对于投资者和技术从业者,这意味着短期内合规成本降低,但长期舆论和法律风险累积。
原文:TechCrunch
LinkedIn新政策难阻AI垃圾内容,平台失控?

是什么:The Decoder发表评论,认为LinkedIn宣布的应对AI生成低质内容的新政策只是承认平台已失去对信息流的控制。
关键点:LinkedIn的新政策将标记AI生成内容并限制其曝光,但评论者指出,平台已无法区分人工创作与AI生成的边界,更无法阻止大规模低质内容生产。这场“战争”在政策层面就已宣告失败。
为什么重要:这不仅是LinkedIn的问题——所有依赖用户生成内容(UGC)的平台都面临AI水军(slop)的侵蚀。对于产品经理和投资人,这意味着平台估值模型中“内容质量”这个变量正在被AI作弊工具彻底扭曲。
原文:The Decoder
学生示威:AI赞歌毕业演讲遭全场嘘声
是什么:多所大学毕业生在毕业典礼上对赞扬AI的演讲报以嘘声,一位演讲者当场回击“deal with it”。
关键点:事件发生在美国多所高校,学生们以一种近乎“文化战争”的姿态抵制过度歌颂AI的演讲。演讲者认为AI将带来机遇,而学生们担心就业替代和伦理问题。回击的演讲者言辞强硬,进一步激化冲突。
为什么重要:这反映了公众尤其是年轻一代对AI的态度分化——不是所有技术乐观主义都会被市场接受。对于科技公司而言,舆论环境正在从“好奇”转向“警惕”,品牌建设需要更多与人文价值的平衡。
BBC揭露:谷歌AI正被操纵,搜索巨头悄然反击

是什么:BBC报道称,谷歌的AI搜索结果正遭受大量恶意操纵,搜索团队正在采取隐蔽手段对抗。
关键点:操纵手段包括虚假关键词堆叠、AI生成内容伪装成权威源、以及利用谷歌AI模型的知识盲点注入虚假信息。谷歌的反击包括动态调整排名算法、设置“欺骗陷阱”来识别恶意内容。BBC称谷歌没有公开讨论这些攻防战。
为什么重要:如果谷歌的AI搜索可以被大规模操纵,那么整个AI搜索商业模式的可靠性将受质疑。对于投资人和产品经理,这意味着依赖AI搜索流量分发的内容生产策略需重新评估,同时SEO(搜索引擎优化)行业将面临范式级重构。
原文:BBC Future
Cloudflare CEO谈如何选择被AI替代的员工
是什么:Cloudflare CEO在WSJ采访中解释其决定哪些岗位由AI替代的考量标准,提到“如果任务可以明确用5步描述,且不需要判断力,就适合自动化”。
关键点:他指出的可替代岗位包括客户支持一线、部分数据分析、以及重复性内容审核。但强调保留需要“上下文理解”和“创造性判断”的角色。这一言论在社交媒体引发大量批评,认为CEO公开量化员工价值过于冷酷。
为什么重要:这是目前最明确的“AI替代决策框架”之一。对于技术管理者,这个框架可以直接用于评估自己团队的脆弱性;对于从业者,这是职业规划的核心信号——需要向“不可编码为五步规则”的技能方向迁移。
今天所有的新闻都在提问同一个问题:当AI商业化的速度碾压治理与人文共识时,谁会先撞上墙?
⚙️ 开源工具
今日开源社区围绕 AI Agent 迎来多项目同日发布——OpenAI 推出了自主编码 Agent 的编排规范 Symphony,Karpathy 发布单 GPU 跑科研的 autoresearch,GitHub 则推出了规范驱动开发的 Spec Kit。标志性信号:Agent 开发正从“手工作坊”走向标准与自动化。
OpenAI 开源 Symphony,定义自主编码 Agent 编排规范
是什么 / 关键点 / 为什么重要
OpenAI 发布了 Symphony SPEC,一个面向自主编码智能体编排的开放标准规范。这不是一个具体产品,而是一套定义了 Agent 之间如何通信、任务如何拆解与分配的协议。核心目的是让不同厂商、不同框架的编码 Agent 能够互操作,类似 HTTP 对于 Web 的意义。对于开源生态而言,这意味着未来顶级的 Agent 工作流(如多 Agent 协作写代码)可能不再绑定单一平台,而是可以自由组合。虽然规范初版,但 OpenAI 的背书有望加速行业采用,降低 Agent 编排的开发成本。
原文:InfoQ
Karpathy 开源 autoresearch:单 GPU 自动跑科研

是什么 / 关键点 / 为什么重要
Andrej Karpathy 发布 autoresearch,一个让 AI 代理自动在单 GPU 上运行 nanochat 训练研究的开源项目。项目基于 PyTorch,Agent 可以自动设计实验、执行训练、收集结果并迭代。关键点:它让单卡用户也能进行一定规模的自动化研究探索,大幅降低了超参搜索和消融实验的人力成本。重要性在于,这是开源界第一次将“科研劳动”本身 Agent 化,可能推动更多小型团队或个人研究者用低成本跑通完整实验链路,加速模型迭代。
火山引擎开源 OpenViking:专为 AI Agent 设计的上下文数据库
是什么 / 关键点 / 为什么重要
火山引擎发布 OpenViking,一个开源的上下文数据库,通过文件系统范式统一管理 Agent 的记忆、资源和技能。它将 Agent 运行所需的上下文(历史对话、知识库、工具配置等)持久化、可查询,并支持版本管理。关键在于:传统 LLM 应用往往把上下文存在内存或简单键值存储中,而 OpenViking 提供了类似文件系统的分层组织,更符合 Agent 长会话场景的需求。重要性在于,这是国内云厂商在 Agent 基础设施层的少有开源贡献,为构建可落地的生产级 Agent 提供了存储基座。
GitHub 发布 Spec Kit,助力规范驱动开发
是什么 / 关键点 / 为什么重要
GitHub 推出开源工具包 Spec Kit,帮助开发者采用 Spec-Driven Development(SDD)方法。SDD 强调先写详细规范描述(类似技术文档),再用工具自动生成代码骨架或约束。Spec Kit 包含模板、命令行工具和 CI 集成示例。关键点:它让“先写规范再写代码”的流程变得可复用,尤其适合 Agent 开发中需要明确定义输入输出行为的场景。重要性在于,GitHub 试图将 Agent 开发者的注意力拉回“界定问题”而不是“调试 Agent 行为”,从方法论上提升 Agent 的可信度。
今天的开源 Agent 发布不约而同指向同一个方向:用标准、数据库和工具链把 Agent 从 Demo 变成工程。下一个改变研发流程的 Agent 工具,会是来自大厂的规范,还是顶级研究者的“玩具”?