今天最值得看的三件事:
- 模型发布 · Gemini 3.5 Flash 正式发布,更快更便宜
- 研究论文 · OpenAI模型破解80年未解数学猜想
- 模型发布 · Google推出全能模型Gemini Omni,支持视频生成
下文按板块展开,正文每条均附原始链接。
🚀 模型发布
导语:2026年5月21日,模型发布板块迎来久违的密集轰炸。Google在I/O上同时亮出Gemini 3.5 Flash(速度4倍提升、成本减半)和全能模型Omni(支持视频生成),直奔“更快、更便宜、更多模态”而去。阿里云则用Qwen3.7-Max专攻Agent场景,意图精准锁定企业需求。如果你在选型或投资,这三款模型定调了未来半年的竞争节奏。
Gemini 3.5 Flash:速度4倍、成本减半,即日可用

是什么:Google在I/O 2026上正式发布Gemini 3.5 Flash,声称推理速度提升4倍,API成本较前代降低50%,在编程和智能体(agentic)基准测试上超越上一代模型。即日起全球可用。关键点:速度提升直接降低了用户延迟敏感型应用的调用门槛,成本减半则可能引发新一轮价格战。为什么重要:对于开发者和B端客户,Flash系列本就主打低成本、高吞吐,Gemini 3.5 Flash的升级意味着更多实时对话、代码补全和Agent编排场景可以商业落地,Google试图用“性价比”挤压竞争对手——尤其是Claude和GPT-4o mini的市场空间。
原文:Google Blog
Gemini Omni:从任意输入到视频生成,多模态再进一步

是什么:Google发布Gemini Omni,一个能从文本、图像、音频甚至视频输入生成任意输出内容(包括视频)的全能模型。关键点:它是Google多模态能力的“天花板”产品,首次实现了“输入视频→输出视频”的端到端生成,意味着用户可以直接用一段视频作为Prompt生成新视频,而不必经过文本中间态。为什么重要:这标志着基础模型从“多模态理解”跨入“多模态原生生成”,对游戏、短视频、虚拟制作等行业可能产生结构性冲击。Gemini Omni与Flash形成高低搭配:Flash跑量和跑敏捷,Omni探索边界。投资者应关注后续API定价——如果成本可控,它可能重定义AI内容生产流程。
阿里云Qwen3.7-Max:Agent专长,中国企业级市场新锚点
是什么:阿里云发布旗舰模型Qwen3.7-Max,专门针对Agent任务(工具调用、多步推理、记忆管理等)进行优化,性能在相关基准上领先。同步升级全栈AI产品体系。关键点:这是国内首个明确为Agent场景设计的旗舰模型,而非通用大模型。阿里云把Agent能力作为核心卖点,侧面呼应市场上“模型同质化”的焦虑——当基础语言能力趋同,任务执行准确率才是差异点。为什么重要:对于企业客户,Agent是落地AI的“高频入口”。Qwen3.7-Max如果真能在实际部署中表现出更低的错误率和更稳定的上下文保持,将直接挑战海外模型在国内的生态优势。同时也暗示阿里云的模型策略从“追参数”转向“抓场景”。
原文:Qwen Blog
Stable Audio 3.0:6分钟歌曲,开源权重可本地运行

是什么:Stability AI发布Stable Audio 3.0,支持生成最长6分钟的音乐作品,同时发布小型模型版本并开放权重,允许本地部署。关键点:6分钟意味着从“片段生成”跨越到“歌曲级创作”,并且开放权重让音乐AI真正进入可复现、可定制的阶段。小型模型能跑在消费级GPU上。为什么重要:开源策略延续了Stability AI在图像领域的路线,进一步挤压闭源音乐生成工具(如MusicLM)的空间。对于BGM、游戏配乐、个人创作者,这是成本最低的AI音乐选项。但版权合规和音频质量仍是商用前的门槛。
原文:The Decoder
Deepseek 开发代码工具 Deepseek Code,直指Claude Code

是什么:Deepseek正在构建类似Claude Code和OpenAI Codex的AI编程助手,内部项目代号Deepseek Code,意图进入开发者工具市场。关键点:目前尚无具体发布时间或demo,但此举表明Deepseek从“基础模型供应商”向“应用层工具”延伸。为什么重要:开发者工具是一个黏性极强的入口,如果Deepseek Code能复用其模型在代码基准上的优势(如DeepSeek-Coder系列),并在价格或本地部署上做差异化,可能威胁当前Claude Code的份额。对中国开发者市场,Deepseek Code可能成为GitHub Copilot之外的国产替代选项。
原文:The Decoder
结语:一天之内,Google占尽风头,但阿里云和Deepseek的“Agent+工具”战术同样值得盯紧——当模型本身趋于同质,哪一家能在真实场景中少出Bug,哪一家就可能赢下企业级市场。
🏢 公司动态
OpenAI在扫清马斯克诉讼障碍后,加速推进IPO,窗口或定于九月。与此同时,xAI财报曝光巨额亏损,但算力战争并未降温——Anthropic每月砸12.5亿美元向xAI买算力。AI行业“军备竞赛”进入资本化新阶段,上市与烧钱并存,市场需要重新评估单点风险。
OpenAI加速推进IPO,或于九月上市

马斯克诉讼案败诉后,OpenAI恢复IPO筹备。据知情人士透露,公司正与投行密集接洽,目标是在2026年9月完成上市。若成行,这将是今年最受瞩目的科技IPO之一。OpenAI目前估值未公开,但此前在一级市场已超1500亿美元。关键点在于:上市将为OpenAI提供更稳定的融资渠道,同时让早期投资者和员工获得流动性。但也意味着将面临更严格的财务披露和季度业绩压力。
原文:TechCrunch
GitHub 遭恶意VSCode扩展入侵,3800个仓库受影响

GitHub确认一次安全事件:攻击者通过恶意VSCode扩展获取了内部访问权限,导致约3800个私有仓库被暴露。GitHub表示已撤销恶意扩展并加强审查流程,但未披露受影响的具体数据。对于技术从业者,这起事件再次敲响警钟:开发工具链的供应链攻击正变得越来越隐蔽。建议团队审计正在使用的VSCode扩展权限,尤其是那些可访问GitHub令牌的扩展。
NVIDIA 财报再创纪录,披露持有43亿美元初创公司股份

NVIDIA最新季度营收再创新高,同时首次公开披露其持有的大量AI初创公司股权,总额达430亿美元。这意味着NVIDIA不仅是算力供应商,也是AI生态的“影子VC”。从投资角度看,NVIDIA对自家芯片依赖性强的企业进行战略投资,既锁定了客户,又分享了成长收益。但投资者需关注这种“既是裁判又是球员”的潜在利益冲突。
原文:TechCrunch
xAI 亏损64亿美元,SpaceX IPO文件曝光财务状况

SpaceX的IPO文件意外展示了旗下xAI的财务情况:2025年亏损64亿美元,收入远不及烧钱速度。xAI计划大规模扩张Grok模型训练,同时面临数据中心发电机诉讼。尽管巨额亏损,xAI依然获得Anthropic每月12.5亿美元的算力订单,表明其自有算力资源已成为稀缺资产。对投资人而言,需要判断xAI能否将算力优势转化为可持续的商业模型。
原文:TechCrunch
Anthropic 将每月向xAI支付12.5亿美元计算资源费用

据TechCrunch报道,Anthropic与xAI签署协议,每月支付12.5亿美元购买其算力。这笔交易总额惊人,2026年将达150亿美元,远超许多AI公司营收。关键在于,这反映了前沿AI训练的算力需求已经大到单一云厂商难以满足,跨公司算力交易成为新常态。同时,也给xAI带来了稳定的现金流,抵消部分亏损。Anthropic则借此绕过微软Azure等竞对云平台的限制。
原文:TechCrunch
Andrej Karpathy 离开OpenAI加入Anthropic

知名AI研究员Andrej Karpathy选择离开OpenAI,加入Anthropic重返前沿大模型研发。Karpathy此前在OpenAI担任重要角色,后短暂离开创业。这次加盟Anthropic,被解读为对OpenAI当前技术路线的不同看法。对于行业观察者,这进一步印证了Anthropic正在快速吸纳顶级人才,与OpenAI形成正面竞争。
原文:The Decoder
Google SynthID 被OpenAI和Nvidia采用,AI水印走向行业标准
Google的AI水印技术SynthID获得OpenAI和Nvidia官方支持,作为内容溯源工具。SynthID可以在生成的图像、音频、文本中嵌入不可见的数字水印,用于鉴别AI生成内容。这标志着行业在面对深度伪造和版权问题时,开始形成统一的技术标准。对产品经理而言,这意味着未来AI应用可能需要内置水印功能以符合监管要求。
原文:OpenAI
Mistral AI 收购 AI 初创公司 Emmi AI

法国AI领军者Mistral AI宣布收购Emmi AI,以增强其在企业AI应用层的能力。Emmi AI专注于低代码AI集成工具,收购后Mistral将加速垂直行业解决方案的落地。对于欧洲AI生态,这是一次典型的“基础模型公司向下游应用延伸”的策略,类似微软收购Nuance的逻辑。
原文:Emmi AI
今天最值得记住的数字:Anthropic每月花12.5亿美元买算力——AI的资本化和硬件绑定已经远超软件时代。当一家公司的IPO窗口与另一家公司的亏损财报同时出现时,你更担心泡沫还是布局?
🔬 研究论文
今天最值得关注的不是又一个语言模型,而是OpenAI的推理模型推翻了自1946年悬而未决的离散几何猜想,并经数学家验证。这意味着AI不再只是辅助计算,而是能够独立发现和证明数学真理。本文将解读这一突破,并覆盖NVIDIA三模式语言模型、AI科研助手药物重定位、以及AI修复漏洞的局限性。
OpenAI模型破解80年未解数学猜想
是什么:OpenAI的推理模型成功推翻了一个自1946年以来的离散几何猜想,结果经数学家验证并获认可。
关键点:该模型不是简单地搜索或枚举,而是通过逻辑推理得出反例,展示了AI在数学领域的创意性发现能力。
为什么重要:传统上数学定理证明依赖人类直觉,AI的这次突破表明推理模型可参与数学前沿研究,可能加速科学探索。
原文:https://openai.com/index/model-disproves-discrete-geometry-conjecture/
NVIDIA发布Nemotron-Labs-Diffusion:三模式语言模型

是什么:NVIDIA发布的Nemotron-Labs-Diffusion支持自回归、扩散并行和自推测解码三种模式,在同等计算资源下生成6倍token。
关键点:相比现有的Qwen3-8B模型,该模型显著提高了生成速度和效率,同时保持输出质量。
为什么重要:这提升了大规模语言模型的部署效率,尤其适合需要实时生成的场景,可降低推理成本。
原文:https://www.marktechpost.com/2026/05/20/nvidia-ai-releases-nemotron-labs-diffusion-a-tri-mode-language-model-with-6x-tokens-per-forward-over-qwen3-8b/
两个AI科研助手成功完成药物重定位任务

是什么:两个AI工具各自独立完成假设生成与数据分析,在药物重定位任务中展现出潜力。
关键点:AI能够从现有药物中发掘新适应症,减少研发周期和成本。但需注意结果仍待临床验证。
为什么重要:这证明了AI科研助手的协作能力,未来可能从根本上改变药物研发流程。
原文:https://arstechnica.com/science/2026/05/two-ai-based-science-assistants-succeed-with-drug-retargeting-tasks/
AI智能体修复局部漏洞但缺乏系统理解

是什么:基准测试显示AI智能体能够独立修复代码漏洞,但在理解系统范围影响方面表现不佳。
关键点:智能体倾向于仅修复局部问题,忽视跨模块连锁反应,暴露出当前系统理解的短板。
为什么重要:这提醒开发者,依赖AI进行安全修复时需人工复核整体架构,否则可能引入新风险。
原文:https://www.infoq.cn/article/mV5rKKvyYP3OvbxJ4boL
当AI开始证明数学定理,我们或许该重新思考人类与机器协作的边界。下一个被AI攻克的会是哪个领域?
📱 应用产品
导语:今天最值得关注的是Google I/O 上搜索正式升级为Agent驱动——用户不再需要反复查询,而是可以创建后台代理自动监控、下单和执行任务。这是搜索从“工具”向“数字员工”的质变,也是今年AI应用层最重要的产品拐点之一。下文梳理今日8条产品动态,按重要性排序。
Google搜索全面Agent化:AI代理永久在线执行任务

Google在I/O 2026宣布搜索升级为Agent驱动,用户可创建后台代理,设定监控数据、自动下单、定期报告等长期任务。代理持续运行,在后台感知环境变化并自主行动。这意味着搜索从“你问它答”变成“你设它做”——用户不再需要主动查询,代理替你盯盘、比价、填表。这背后依赖Gemini的推理能力和长上下文,但真正突破在于“永久在线”和“可执行”的范式切换。
原文:Ars Technica
Google发布Antigravity 2.0:独立的Agent原生平台

Antigravity 2.0作为独立桌面应用发布,提供CLI、SDK、托管执行和企业级支持,全面替代此前Gemini CLI。这是Google首个专为代理(agent)设计的原生平台:开发者可用CLI创建、调试、部署代理,SDK支持Python/TypeScript,托管服务自动处理扩缩容与持久化。对于技术团队,这意味着Agent开发门槛大幅降低——不再需要自行管理基础设施,一个命令即可上线永久运行的AI worker。
原文:MarkTechPost
Google Genie世界模型结合街景,生成可探索实景世界
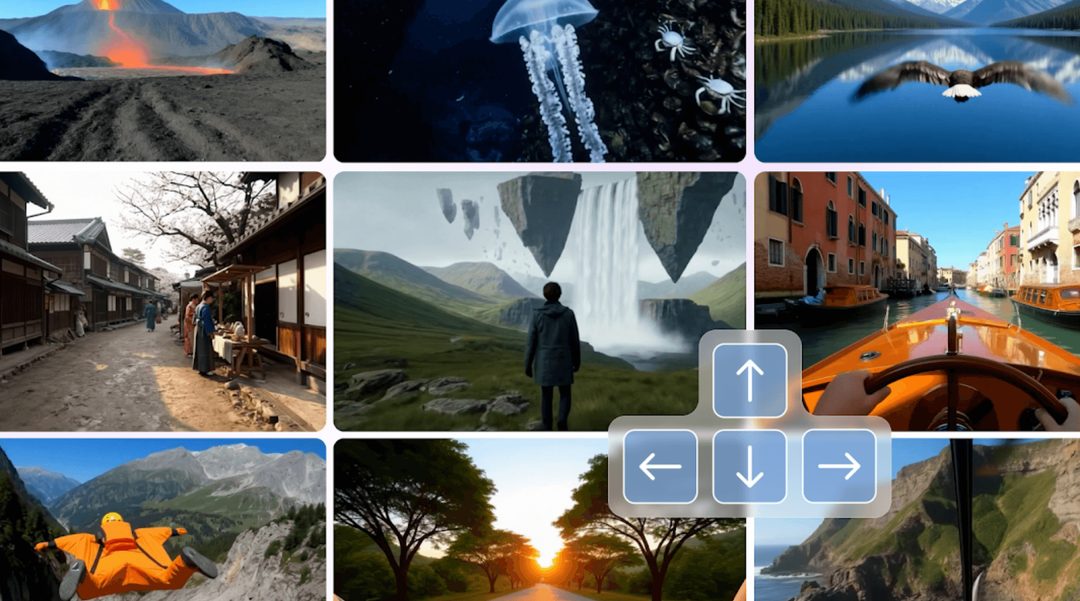
DeepMind将Genie世界模型与Google街景数据结合,创造基于真实地点的交互式3D模拟。用户可进入任意街景位置,自由行走、改变视角、与物体交互。这对游戏开发、机器人训练、虚拟旅游有直接价值:开发者不用手动建模,AI自动从真实场景中生成可探索的虚拟世界。本质上,这是世界模型从演示demo走向实用产品的重要一步。
原文:The Decoder
Google发布AI智能眼镜,语音交互加持Gemini

Google推出音频智能眼镜,支持语音命令直接唤醒Gemini,可实时翻译、导航、搜索,外形与普通眼镜接近,对标Meta Ray-Ban。关键差异在于:Google眼镜默认集成Gemini Live,可进行多轮对话和跨应用操作。对开发者而言,这意味着语音交互+视觉AI(眼镜内置摄像头)的软硬件入口正在成形,应用场景从“翻译器”延伸到“AI副驾”。
原文:TechCrunch
Figma 加入AI助手,自然语言驱动设计
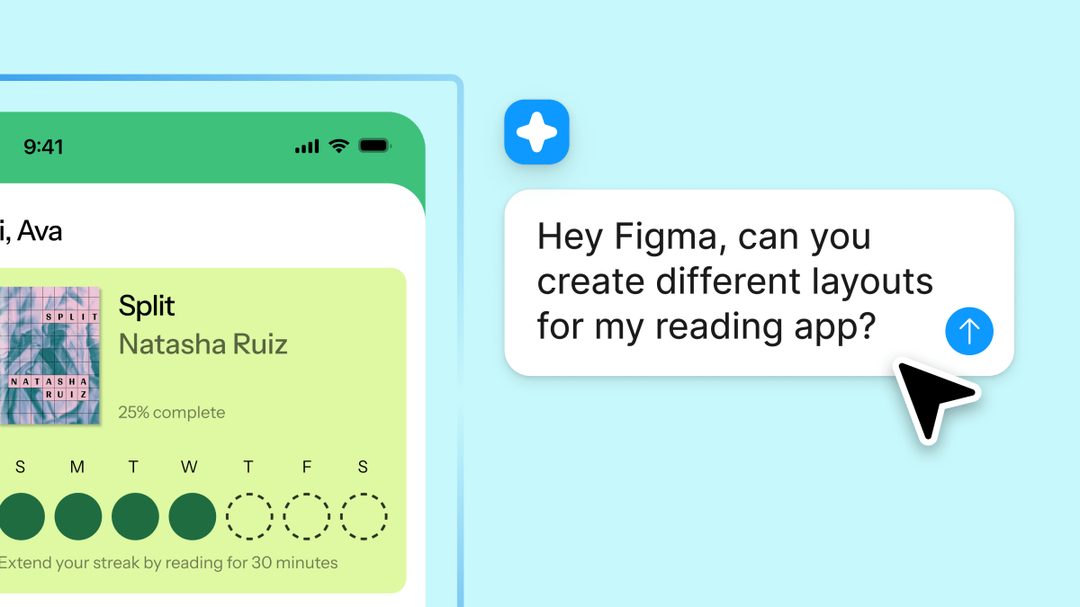
Figma发布AI agent,用户可通过自然语言指令直接生成界面、编辑元素,并自动化重复任务(如批量改样式、生成组件变体)。这是设计工具从“手动拖拽”到“口语化操控”的转折。产品经理和设计师可通过一句话快速产出线框图,开发者可要求AI生成符合设计系统的代码片段。值得关注的是Figma强调“人工确认”环节,避免完全自动化带来的失控风险。
原文:TechCrunch
Anthropic 推出Routines for Claude Code,自动化工作流

Anthropic发布Claude Code的Routines功能:用户可录制并保存一组开发操作(如代码审查、测试生成、文件重构),之后一键重复执行。这实质上是把Claude Code从一个对话助手升级为可配置的自动化Worker。对于开发者,Routines可将高频重复的编码工作流委托给AI,同时保持对每个步骤的控制。这与Google的Agent化思路类似,但更聚焦代码场景,且强调“可回放”。
原文:InfoQ中国
Google Gmail 新增AI语音搜索,对话式检索邮件

Gmail引入语音AI搜索,用户可用自然语言查找邮件,例如“帮我找出上周三和财务部关于预算的邮件”或“显示所有带附件的未读邮件”。基于Gemini,支持多轮对话和上下文理解。这是搜索入口从文本转向语音的自然延伸,也意味着Google将其核心Agent能力嵌入高频应用——收发邮件,从而提高用户粘性和数据闭环。
原文:TechCrunch
Cloudflare Workflows V2 支持5万并发工作流

Cloudflare推出Workflows V2,实现确定性执行和5万并发工作流,适合大规模AI任务编排(如批量数据流水线、Agent多步骤协同)。核心升级:1)内置重试和持久化,保证每个任务不丢;2)支持条件分支和循环,可编排复杂AI agent逻辑。对于工程团队,这意味着可以用较低成本运行海量AI worker,而无需管理消息队列和状态存储。
原文:InfoQ中国
结语:当搜索、设计、开发工具都开始“永久在线”地替你干活,你的下一个问题可能不是“搜什么”,而是“该让代理做什么?”
💭 行业观点
导语:LinkedIn 公开承认平台已被 AI 生成的低质量内容淹没,这不仅是政策更新,更是对算法治理失败的罕见自白。与此同时,毕业生在毕业典礼上集体喝倒彩,讽刺 AI 赞歌,而 DeepMind CEO 则主张用 AI 提升产能而非裁员——行业信心与公众情绪之间的裂缝正在扩大。
LinkedIn承认AI垃圾信息失控,平台治理形同虚设

LinkedIn 宣布推出新政策打击 AI 生成的低质量内容,包括降低“纯 AI 生成帖”的推荐权重,并要求用户标注 AI 辅助创作内容。然而,这一举措被业内解读为变相的认输——平台已无法有效区分人机内容,信息流正在被自动生成的“垃圾”内容淹没。
关键点在于:LinkedIn 的商业模式依赖用户原创的专业讨论,但 AI 内容的大量涌入稀释了真实性,且平台长期缺乏严格审核机制。此次政策被批评为“事后补救”,而非预防性设计。
为什么重要:LinkedIn 是职场社交的权威平台,其失控信号说明 AI 对内容生态的冲击已从娱乐蔓延至专业领域。若头部平台无法自我纠偏,用户信任可能加速瓦解,倒逼更严格的监管介入。
原文:https://the-decoder.com/linkedins-war-on-ai-slop-is-not-just-a-policy-update-it-is-an-admission-that-the-platform-lost-control-of-its-feed/
毕业生集体嘘AI赞歌,科技乐观主义遇冷
多所大学在毕业典礼上出现罕见一幕:当演讲者称赞 AI 将带来无限机遇时,台下毕业生发出嘘声和倒彩。有演讲者当场回怼“接受现实吧”,却招致更猛烈的抗议。事件背后是毕业生对 AI 取代岗位、加剧不平等的深层焦虑。
关键点在于:这并非孤立事件,而是 Z 世代对科技神话的集体反叛。他们亲历 ChatGPT 引发的招聘收缩和技能贬值,对“AI 让世界更美好”的叙事天然不信任。
为什么重要:毕业典礼的嘘声是民意最直接的温度计。当未来劳动力开始拒绝乐观叙事,企业 AI 策略的社会接受度将面临更严峻考验——技术再强,也需面对人心的买单意愿。
原文:https://www.tomshardware.com/tech-industry/artificial-intelligence/college-students-drown-out-ai-praising-commencement-speeches-with-boos-deal-with-it-one-speaker-fires-back-as-students-heckle-positive-pitches-for-ais-role
DeepMind CEO称AI裁员很蠢,应扩大业务而非缩减人力

DeepMind 联合创始人兼 CEO Demis Hassabis 在采访中直言:用 AI 替代人类员工是短视行为。他认为公司应利用 AI 提升的生产力去开拓新业务、创造新岗位,而非简单地裁员降本。他批评当前企业“成本优先”的思路忽略了长期创新潜力。
关键点:Hassabis 并非站在道德高地,而是从商业逻辑出发——AI 的真正红利在于扩大市场蛋糕,而非切分现有蛋糕。他举了 Google 搜索结合 AI 后新功能带来额外收入的例子。
为什么重要:这一观点与硅谷主流裁员潮形成鲜明对比。作为技术领袖,Hassabis 的声音为“人机协作”而非“人机替换”提供了可操作的叙事。如果更多公司采纳,AI 对就业的冲击可能从“替代模式”转向“增值模式”。
原文:https://www.wired.com/story/demis-hassabis-ai-layoffs-deepmind-google-io/
AI成本过高:模型涨价引发开发者担忧

近一周内,包括 Gemini 3.5 Flash 在内的多款模型宣布涨价,涨幅在 20%–50% 不等。开发者社区普遍感到焦虑——AI 推理成本非但未如预期下降,反而因训练复杂度提升而持续攀升。小团队和个人开发者开始重新评估依赖 API 的性价比。
关键点:涨价背后是芯片短缺、能源成本上升以及模型规模的军备竞赛。其中 Gemini 3.5 Flash 的文档号称“价格调整反映了基础设施进步”,但开发者实测发现同等任务成本翻倍。
为什么重要:低成本曾是 AI 应用爆发的核心假设。如果模型持续涨价,依赖 API 的创业公司将面临成本倒挂,而大厂可能借此巩固垄断地位。行业需要新的推理优化方法或替代方案(如本地模型)来避免生态僵化。
原文:https://www.wheresyoured.at/ai-is-too-expensive/
结语:当平台、用户、开发者、技术领袖四方的信号都指向“不适”,AI 行业或许该问一问:技术乐观主义是否只是部分人的自嗨?
⚙️ 开源工具
开源社区再次证明,不依赖闭源巨头也能解决Agent可靠性难题。今天最值得关注的项目是 Forge——一个自托管的LLM调用守卫层,将开源小模型的Agent任务准确率从53%拉升至99%。这组数据意味着:通过轻量级工程手段,开源模型在工具使用场景下已可匹敌GPT-4级别表现,而成本与隐私优势更突出。
Forge:开源守卫层让小模型Agent准确率从53%升至99%
是什么: Forge是一个自托管(self-hosted)的LLM工具调用可靠性层,专为开源模型设计。它通过守卫机制(guardrails)检验模型输出的每一步工具调用,拦截无效操作并重新生成。
关键点: 示例数据显示,某开源小模型在未使用Forge时Agent任务准确率仅53%,叠加守卫层后飙升至99%。该方案完全本地部署,不依赖外部API,意味着开发者可在敏感数据场景下使用。
为什么重要: Agent可靠性是阻碍生产落地的核心痛点。Forge证明工程优化能弥补模型能力差距,使小模型替代大模型成为可能,同时降低token成本和隐私风险。
原文:https://github.com/antoinezambelli/forge
Anthropic 官方发布 Claude Skills 目录和插件仓库
是什么: Anthropic 推出官方 Claude Code 插件目录及 Skills 仓库,汇集经过审核的高质量技能和社区贡献的插件。
关键点: 该仓库(github.com/anthropics/skills)包含可直接复用的技能模块,社区可提交PR贡献。与第三方插件生态不同,官方维护的目录在兼容性和安全性上更有保障。
为什么重要: 类似于VS Code的插件市场,标准化技能目录将加速Claude Code在开发场景的普及,降低开发者编写自定义agent的门槛,同时确立Anthropic在agent生态中的话语权。
原文:https://github.com/anthropics/skills
OpenHuman:开源个人AI超级智能,注重隐私
是什么: OpenHuman 是一个开源项目,旨在提供私有、简单的个人AI助手,强调“超级智能”能力与隐私保护并重。
关键点: 项目描述提及“功能强大”,但具体技术细节未充分展开。其核心卖点是本地运行、不联网(推测),用户数据完全由自己掌控。
为什么重要: 个人AI助手产品层出不穷,但多数依赖云端。OpenHuman 回应了用户对数据主权的焦虑,若能在功能上接近主流产品,将开辟一条独立于大厂的道路。
原文:https://github.com/tinyhumansai/openhuman
CLI-Anything:让所有软件变成Agent原生接口

是什么: CLI-Anything 通过命令行接口将各种软件改造为AI agent可以调用的原生接口,打通agent与任意软件间的交互通道。
关键点: 项目来自HKUDS,核心思路是“工具即CLI”。任何有命令行界面的软件,通过该工具即可暴露为agent可调用的函数。
为什么重要: 当前agent可操作的工具集受限于API开放程度。CLI-Anything 理论上能让agent操控几乎所有桌面软件(如浏览器、IDE、设计工具),极大扩展agent与现实世界的交互边界。
原文:https://github.com/HKUDS/CLI-Anything
CodeGraph:本地代码知识图提升AI编码效率
是什么: CodeGraph 为Claude Code、Cursor等AI编码工具提供预索引的本地代码知识图,用于提升代码理解和生成效率。
关键点: 通过预先建立项目代码的知识图,AI工具可快速定位相关代码片段,减少上下文重复加载带来的token消耗和工具调用次数。
为什么重要: 大项目中的AI编码体验常受限于上下文窗口。CodeGraph 用离线索引降低实时搜索成本,长期来看可能成为AI编码工具的标准配套组件。
原文:https://github.com/colbymchenry/codegraph
agentmemory:AI编码代理持久化记忆库
是什么: agentmemory 是一个基于基准测试第一的持久化记忆方案,专为AI编码代理提供长期记忆能力。
关键点: 项目宣称在相关基准上排名第一,支持结构化记忆存储与检索,可让agent在多次会话之间保留对项目、用户偏好的记忆。
为什么重要: 持久化记忆是agent从“单次对话”迈向“持续协作”的关键。agentmemory 若能在编码场景稳定工作,将直接提升agent处理长期任务的能力。
原文:https://github.com/rohitg00/agentmemory
CloakBrowser:防检测隐身浏览器,通过所有bot测试
是什么: CloakBrowser 是一款基于Chromium的隐身浏览器,能够绕过所有主流bot检测机制,可作为Playwright的直接替代品。
关键点: 项目自称通过所有bot测试(如Cloudflare Turnstile等),底层使用反指纹技术模拟真实用户环境。无需修改现有脚本即可替换Playwright。
为什么重要: Web自动化(爬虫、测试、AI数据收集)最大障碍是被识别为bot。CloakBrowser 提供了一个开源方案,让开发者和AI agent能更稳定地访问网站,但需注意合规边界。
原文:https://github.com/CloakHQ/CloakBrowser
RTK (Rust Token Killer):减少LLM token消耗60-90%
是什么: RTK 是一个纯Rust编写的CLI代理,通过缓存和压缩技术大幅降低常见开发命令(如git log、cat等)在LLM调用中的token消耗。
关键点: 项目声称可将token消耗减少60-90%,意味着同样的一行命令原本消耗1000 token,现在仅需100-400。基于Rust实现,性能优越。
为什么重要: Token成本是LLM应用的核心开销之一。RTK 通过预处理和压缩,让高频命令的token消耗大幅下降,尤其适合agent频繁调用工具的场景,可直接降低运营成本。
原文:https://github.com/rtk-ai/rtk
当每个工具都成为Agent的“手指”,你的开发流程会被如何重塑?